QNLP Tutorial#
We go through the basics of DisCoPy and quantum natural language processing (QNLP).
On the menu:
Drawing cooking recipes#
An Ty (type) can be thought as a list of ingredients in a recipe, for example:
[1]:
from discopy.symmetric import Ty
print(Ty('sentence', 'qubit'))
sentence @ qubit
Technically, types form a free monoid with @ (tensor) as product and Ty() (the empty type) as unit.
[2]:
egg, white, yolk = Ty(*['egg', 'white', 'yolk'])
assert egg @ (white @ yolk) == (egg @ white) @ yolk # associativity
assert egg @ Ty() == egg == Ty() @ egg # unitality
Once we have defined some types, we can draw a Box with some types as dom (domain) and cod (codomain) which represent the inputs and outputs of a process. Note that we draw all our diagrams top to bottom.
[3]:
from discopy.symmetric import Box
crack = Box(name='crack', dom=egg, cod=white @ yolk)
crack.draw(figsize=(2, 2))
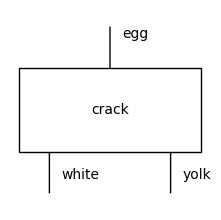
We can put boxes side by side with @ (tensor) and compose them in sequence with >> (then).
[4]:
mix = Box('mix', white @ yolk, egg)
crack_tensor_mix = crack @ mix
crack_then_mix = crack >> mix
from discopy.drawing import Equation
Equation(crack_tensor_mix, crack_then_mix, symbol=' and ').draw(space=2, figsize=(8, 2))
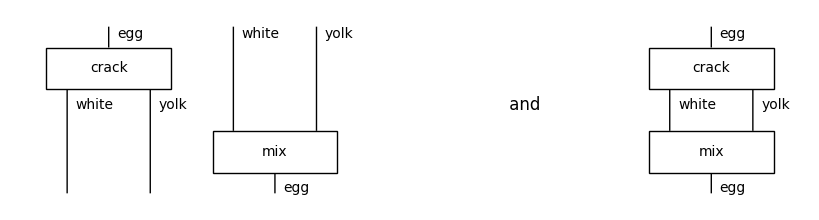
We can draw the Id (identity) for a type, i.e. just some parallel wires. Composing with an identity does nothing. Tensoring with Id() (the empty diagram) does nothing either.
[5]:
from discopy.symmetric import Id
assert crack >> Id(white @ yolk) == crack == Id(egg) >> crack
assert crack @ Id() == crack == Id() @ crack
If we tensor a diagram f with a type x, it implicitly calls Id (technically, this is called whiskering).
[6]:
assert crack @ egg == crack @ Id(egg)
assert egg @ crack == Id(egg) @ crack
sugar, yolky_paste = Ty('sugar'), Ty('yolky_paste')
beat = Box('beat', yolk @ sugar, yolky_paste)
crack_then_beat = crack @ sugar >> white @ beat
crack_then_beat.draw(figsize=(3, 2))
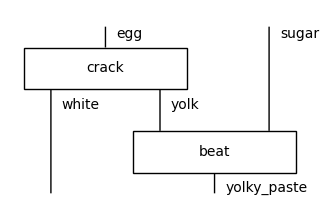
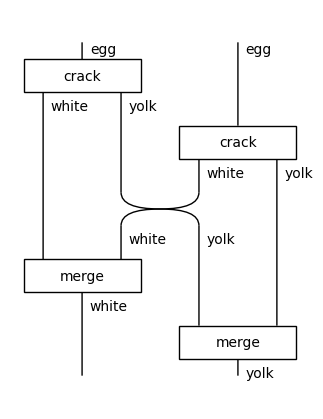
We can change the order of ingredients using special boxes called Swap. This is needed for cooking indeed some recipes cannot be written on the plane. For example:
[7]:
from discopy.symmetric import Swap
merge = lambda x: Box('merge', x @ x, x)
crack_two_eggs = crack @ crack\
>> white @ Swap(yolk, white) @ yolk\
>> merge(white) @ merge(yolk)
crack_two_eggs.draw(figsize=(3, 4))
Exercise: Draw your favorite cooking recipe as a diagram. You’ll want to keep your ingredients in order if you want to avoid swapping them too much.
Reading: Check out Pawel’s blogpost Crema di mascarpone and diagrammatic reasoning.
Exercise: Define a function that takes a number n and returns the recipe of a tiramisu with n layers of crema di mascarpone and savoiardi.
Exercise (harder): Define a function that takes a number n and returns the recipe for cracking n eggs.
Anything we can draw using boxes, tensor, composition and identities is called a Diagram. A diagram is uniquely defined by a domain, a codomain, a list of boxes and a list of offsets. The offset of a box encodes its \(x\)-coordinate as the number of wires passing to its left, its \(y\)-coordinate is given by its index in the list. For example:
[8]:
from discopy.symmetric import Diagram
assert crack_two_eggs == Diagram.decode(
dom=egg @ egg, boxes_and_offsets=[
(crack, 0),
(crack, 2),
(Swap(yolk, white), 1),
(merge(white), 0),
(merge(yolk), 1)])
While Diagram is the core data structure of DisCoPy, Functor is its main algorithm. It is initialised by two mappings:
obmaps objects (i.e. types of length1) to types,armaps boxes to diagrams.
The functor takes a diagram, substitute each box by its image under the ar mapping and returns the resulting diagram. We can use this to “open a box”, for example:
[9]:
from discopy.symmetric import Functor
crack2 = Box("crack", egg @ egg, white @ yolk)
open_crack2 = Functor(
ob_map=lambda x: x,
ar_map={crack2: crack_two_eggs, beat: beat})
crack2_then_beat = crack2 @ Id(sugar) >> Id(white) @ beat
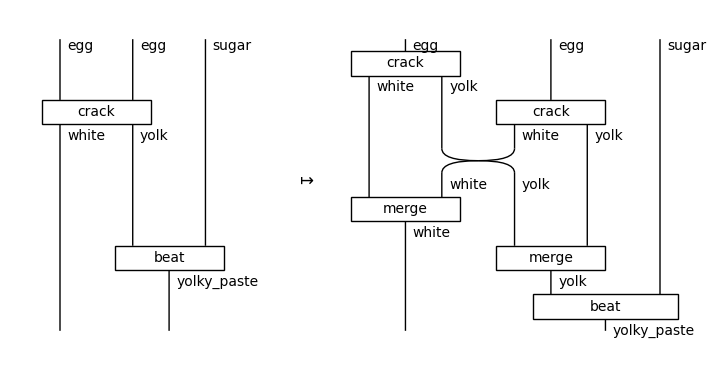
Equation(crack2_then_beat, open_crack2(crack2_then_beat),
symbol='$\\mapsto$').draw(figsize=(7, 3.5))
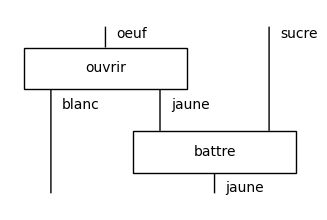
Another example of a functor is the translation from English cooking to French cuisine.
[10]:
oeuf, blanc, jaune, sucre = Ty("oeuf"), Ty("blanc"), Ty("jaune"), Ty("sucre")
ouvrir = Box("ouvrir", oeuf, blanc @ jaune)
battre = Box("battre", jaune @ sucre, jaune)
english2french = Functor(
ob_map={egg: oeuf,
white: blanc,
yolk: jaune,
sugar: sucre,
yolky_paste: jaune},
ar_map={crack: ouvrir,
beat: battre})
english2french(crack_then_beat).draw(figsize=(3, 2))
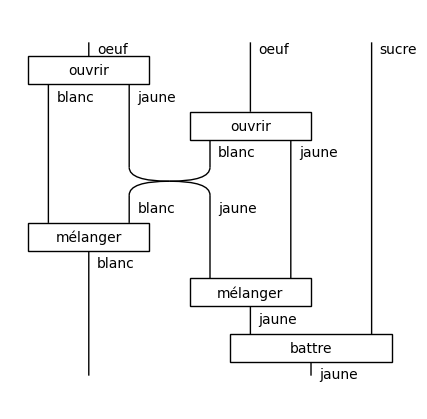
Functors compose just like Python functions, e.g.
[11]:
echanger = lambda x, y: Box("échanger", x @ y, y @ x, draw_as_wires=True)
melanger = lambda x: Box("mélanger", x @ x, x)
for x in [white, yolk]:
english2french.ar_map[merge(x)] = melanger(english2french(x))
english2french(open_crack2(crack2_then_beat)).draw(figsize=(4, 4))
Exercise: Define a functor that translate your favorite language to English, try composing it with english2french.
Exercise: Define a french2english functor, check that it’s the inverse of english2french on a small example.
Tensors as boxes#
Sadly, Python is not very good at cooking, it doesn’t even have a proper coffee module. There is one thing that Python’s numpy package is good at though: computing with multi-dimensional arrays, a.k.a. tensors. We can interpret tensors as cooking steps with the dimensions of their axes as ingredients, i.e. tensors are boxes.
Dim (dimension) is a subclass of Ty where the objects are integers greater than 1, with multiplication as tensor and the unit dimension Dim(1). Tensor is a subclass of Box defined by a pair of dimensions dom, cod and an array with shape dom @ cod.
[12]:
from discopy.tensor import Dim, Tensor
matrix = Tensor([0, 1, 1, 0], Dim(2), Dim(2))
matrix.array
[12]:
array([[0, 1],
[1, 0]])
Composition is given by matrix multiplication, with Tensor.id as identity, e.g.
[13]:
assert matrix >> Tensor.id(Dim(2)) == matrix == Tensor.id(Dim(2)) >> matrix
vector = Tensor([0, 1], Dim(1), Dim(2))
vector >> matrix
[13]:
Tensor[int64]([1, 0], dom=Dim(1), cod=Dim(2))
Tensor is given by the Kronecker product, with Tensor.id(Dim(1)) as unit, e.g.
[14]:
assert Tensor.id(Dim(1)) @ matrix == matrix == matrix @ Tensor.id(Dim(1))
Tensor.id(Dim(1))
[14]:
Tensor[int64]([1], dom=Dim(1), cod=Dim(1))
[15]:
vector @ vector
[15]:
Tensor[int64]([0, 0, 0, 1], dom=Dim(1), cod=Dim(2, 2))
[16]:
vector @ matrix
[16]:
Tensor[int64]([0, 0, 0, 1, 0, 0, 1, 0], dom=Dim(2), cod=Dim(2, 2))
In practice, both composition and tensor are computed using numpy.tensordot and numpy.moveaxis.
[17]:
import numpy as np
assert np.all(
(matrix >> matrix).array == matrix.array.dot(matrix.array))
assert np.all(
(matrix @ matrix).array == np.moveaxis(np.tensordot(
matrix.array, matrix.array, 0), range(4), [0, 2, 1, 3]))
We can compute the conjugate transpose of a tensor using Tensor.dagger.
[18]:
matrix = Tensor[complex]([0, -1j, 1j, 0], Dim(2), Dim(2))
matrix >> matrix.dagger()
[18]:
Tensor[complex]([1.+0.j, 0.+0.j, 0.+0.j, 1.+0.j], dom=Dim(2), cod=Dim(2))
Thus, we can compute the inner product of two vectors as a scalar tensor.
[19]:
vector1 = Tensor[complex]([-1j, 1j], Dim(1), Dim(2))
vector.cast(complex) >> vector1.dagger()
[19]:
Tensor[complex]([0.-1.j], dom=Dim(1), cod=Dim(1))
We can add tensors elementwise, with the unit given by Tensor.zero.
[20]:
vector + vector
[20]:
Tensor[int64]([0, 2], dom=Dim(1), cod=Dim(2))
[21]:
zero = Tensor.zero(Dim(1), Dim(2))
assert vector + zero == vector == zero + vector
We can reorder the axes of the domain or codomain of a tensor by composing it with Tensor.swap.
[22]:
swap = Tensor.swap(Dim(2), Dim(3))
assert swap.dom == Dim(2) @ Dim(3) and swap.cod == Dim(3) @ Dim(2)
assert swap >> swap.dagger() == Tensor.id(Dim(2, 3))
assert swap.dagger() >> swap == Tensor.id(Dim(3, 2))
matrix1 = Tensor(list(range(9)), Dim(3), Dim(3))
assert vector @ matrix1 >> swap == matrix1 @ vector
In order to turn a domain axis into a codomain axis or vice-versa, we can “bend the legs” of a tensor up and down using Tensor.cups and Tensor.caps.
[23]:
cup, cap = Tensor.cups(Dim(2), Dim(2)), Tensor.caps(Dim(2), Dim(2))
print("cup == {}".format(cup))
print("cap == {}".format(cap))
cup == Tensor[int64]([1, 0, 0, 1], dom=Dim(2, 2), cod=Dim(1))
cap == Tensor[int64]([1, 0, 0, 1], dom=Dim(1), cod=Dim(2, 2))
[24]:
_id = Tensor.id(Dim(2))
assert cap @ _id >> _id @ cup == _id == _id @ cap >> cup @ _id
The assertion just above is called the snake equation. It is pretty hard to see where this name come from by looking at the formula, but all three sides of the equation are indeed equal tensors.
[25]:
print("\n == ".join(map(str, (cap @ _id >> _id @ cup, _id, _id @ cap >> cup @ _id))))
Tensor[int64]([1, 0, 0, 1], dom=Dim(2), cod=Dim(2))
== Tensor[int64]([1, 0, 0, 1], dom=Dim(2), cod=Dim(2))
== Tensor[int64]([1, 0, 0, 1], dom=Dim(2), cod=Dim(2))
In order to draw a more meaningful equation, we need to draw diagrams, not arrays. We can use the special Cup and Cap boxes to draw bended wires.
[26]:
from discopy.tensor import Cup, Cap, Id
left_snake = Cap(Dim(2), Dim(2)) @ Id(Dim(2)) >> Id(Dim(2)) @ Cup(Dim(2), Dim(2))
right_snake = Id(Dim(2)) @ Cap(Dim(2), Dim(2)) >> Cup(Dim(2), Dim(2)) @ Id(Dim(2))
Equation(left_snake, Id(Dim(2)), right_snake).draw(figsize=(5, 2), wire_labels=False)
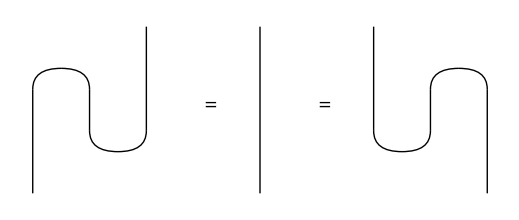
Two diagrams that are drawn differently cannot be equal Python objects: they have different lists of boxes and offsets. What we can say however, is that the diagrams are interpreted as the same Tensor box. This interpretation can be computed using a tensor.Functor, defined by two mappings: ob from type to dimension (e.g. qubit to Dim(2)) and ar from box to array (e.g. X to [0, 1, 1, 0]). For now let’s take these two mappings to be identity functions.
[27]:
from discopy import tensor
_eval = tensor.Functor(
ob_map=lambda x: x,
ar_map=lambda f: f)
assert _eval(left_snake) == _eval(Id(Dim(2))) == _eval(right_snake)
A tensor.Diagram, also called a tensor network, is a subclass of Diagram equipped with such an eval method. A tensor.Box, also called a node in a tensor network, is a subclass of Box equipped with an attribute array. The evaluation a tensor diagram, i.e. the tensor.Functor that maps each box to its array, is also called tensor contraction.
The distinction between a tensor.Diagram and its interpretation as a Tensor is crucial. Indeed, two diagrams that evaluate to the same tensor may take very different times to compute. For example, cups and caps allows us to define the transpose of a matrix as a diagram:
[28]:
f = tensor.Box("f", Dim(2), Dim(2), data=[1, 2, 3, 4])
Equation(f.transpose(), f.r).draw(figsize=(3, 2), wire_labels=False)
assert f.r.eval() == f.transpose().eval()
print(f.r.eval())
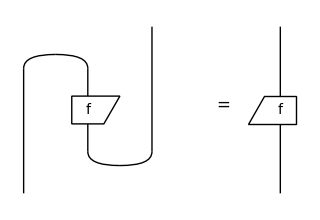
Tensor[int64]([1, 3, 2, 4], dom=Dim(2), cod=Dim(2))
[29]:
%timeit f.transpose().transpose().eval()
3.72 ms ± 71.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
[30]:
%timeit f.eval()
18.6 µs ± 57.3 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Exercise: Check out the Diagram.snake_removal method in the docs. This can greatly speed up the evaluation of tensor diagrams!
Exercise: Define a function that takes a number n and returns the diagram for a matrix product state (MPS) with n particles and random entries. Check how the evaluation time scales with the size of the diagram.
Exercise: Install the tensornetwork library and use it to contract the MPS diagrams more efficiently by passing a contract to the eval method, see the docs.
Quantum circuits#
A (pure) quantum Circuit is simply a recipe with qubits as ingredients and QuantumGate boxes as cooking steps. A quantum gate is defined by a number of qubits and a unitary matrix.
[31]:
from discopy.quantum import qubit, H, Id, CX, QuantumGate
assert H == QuantumGate("H", qubit, qubit, data=[2 ** -0.5 * x for x in [1, 1, 1, -1]], is_dagger=None, z=None)
circuit = H @ qubit >> CX
circuit.draw(figsize=(2, 2), wire_labels=True, margins=(.1, .1))
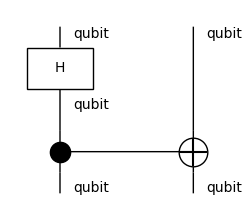
A pure quantum circuit can be evaluated as a Tensor object, i.e. it is a subclass of tensor.Diagram.
[32]:
assert circuit.eval() == H.eval() @ Id(qubit).eval() >> CX.eval()
Pure quantum circuits are reversible. We call the reverse of a circuit its dagger, written with the operator [::-1].
[33]:
print(circuit[::-1])
circuit[::-1].draw(figsize=(2, 2), margins=(.1,.1))
CX >> H @ qubit
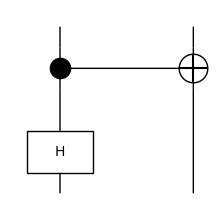
[34]:
assert (CX >> CX[::-1]).eval() == Id(qubit ** 2).eval()
assert (H >> H[::-1]).eval().is_close(Id(qubit).eval())
Matrix multiplication is fun and all, but that’s not really what quantum computers do. To simulate the quantum state that the circuit produces, we need to pre-compose it with a Ket, i.e. we need to initialise some qubits before we apply our circuit. In our example circuit, the resulting state is the so called Bell state \(\frac{1}{\sqrt{2}} (|00\rangle + |11\rangle)\).
[35]:
from discopy.quantum import Ket
(Ket(0, 0) >> circuit).draw(figsize=(2, 2.5))
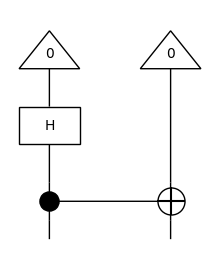
[36]:
(Ket(0, 0) >> circuit).eval()
[36]:
Tensor[complex]([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j], dom=Dim(1), cod=Dim(2, 2))
To compute the probability of a particular measurement result, we need to post-compose our circuit with a Bra, the dagger of Ket, then apply the Born rule.
[37]:
from discopy.quantum import Bra
experiment = Ket(0, 0) >> circuit >> Bra(0, 0)
amplitude = experiment.eval().array
print(f"amplitude: {amplitude}")
experiment.draw(figsize=(2, 3))
print(f"probability: {abs(amplitude) ** 2}")
amplitude: (0.7071067811865476+0j)
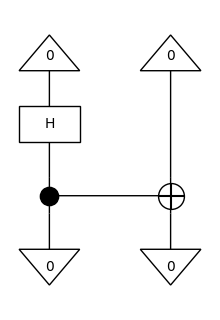
probability: 0.5000000000000001
If we want to get the probability distribution over bitstrings, we need to leave the realm of purity to consider mixed quantum circuits with both bit and qubit ingredients. The Measure box has dom=qubit and cod=bit. Another example of a mixed box is Discard which computes a partial trace over a qubit. Mixed circuits cannot be evaluated as a unitary matrix anymore. Instead whenever the circuit is mixed, circuit.eval() outputs a Channel: a numpy.ndarray with
axes for the classical and quantum dimensions of the circuit.
[38]:
from discopy.quantum import Measure, Discard
print(Discard().eval())
print(Measure().eval())
Channel([1.+0.j, 0.+0.j, 0.+0.j, 1.+0.j], dom=Q(Dim(2)), cod=CQ())
Channel([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 1.+0.j], dom=Q(Dim(2)), cod=Q(Dim(2)))
[39]:
(Ket(0, 0) >> circuit >> Measure() @ Discard()).draw(figsize=(2, 4))
(Ket(0, 0) >> circuit >> Measure() @ Discard()).eval()
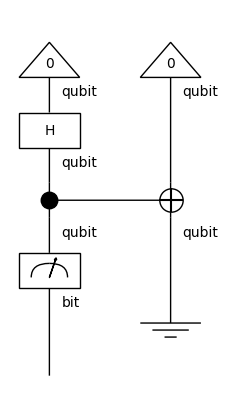
[39]:
Channel([0.5+0.j, 0.5+0.j], dom=CQ(), cod=Q(Dim(2)))
Note that as for diagrams of cooking recipes, we need to introduce swaps in order to apply two-qubit gates to non-adjacent qubits. These swaps have no physical meaning, they are just an artefact of drawing circuits in 2 dimensions rather than 4. Indeed, we can forget about swaps by compiling our planar diagram into the graph-based data structure of the :math:mathrm{t|ketrangle}` compiler <CQCL/tket>`__.
[40]:
from discopy.quantum import SWAP
circuit.to_tk()
[40]:
tk.Circuit(2).H(0).CX(0, 1)
[41]:
(SWAP >> circuit >> SWAP).to_tk()
[41]:
tk.Circuit(2).H(1).CX(1, 0)
We can execute our circuit on a \(\mathrm{t|ket\rangle}\) backend (simulator or hardware) by passing it as a parameter to eval, see the docs.
Exercise: Run your own Bell experiment on quantum hardware! You can use IBMQ machines for free, if you’re ready to wait.
Exercise: Draw a circuit that evaluates to the GHZ state \(\frac{1}{\sqrt{2}} (|000\rangle + |111\rangle)\).
Exercise (harder): Define a function that takes a number n and returns a circuit for the state \(\frac{1}{\sqrt{2}} (|0...0\rangle + |1...1\rangle)\).
DisCoCat#
So far we’ve learnt how to draw diagrams of cooking recipes and how to evaluate quantum circuits. Now we’re gonna see that diagrams can represent grammatical structure. The basic ingredients are grammatical types: n for noun, s for sentence, etc. Each ingredient has left and right adjoints n.l and n.r which represent a missing noun on the right and left respectively. For example, the type for intransitive verbs n.r @ s reads “take a noun on your left and give a sentence”.
The cooking steps are of two kinds: words and cups. Words have no inputs, they output their own grammatical type. Cups have no outputs, they take as inputs two types left and right that cancel each other, i.e. such that left.r == right. The recipe for a sentence goes in three steps:
Tensor the word boxes together.
Compose with cups and identities.
Once there is only the sentence type
sleft, you parsed the sentence!
For example:
[42]:
from discopy.grammar.pregroup import Ty, Id, Word, Cup, Diagram
n, s = Ty('n'), Ty('s')
Alice = Word("Alice", n)
loves = Word("loves", n.r @ s @ n.l)
Bob = Word("Bob", n)
grammar = Cup(n, n.r) @ s @ Cup(n.l, n)
sentence = Alice @ loves @ Bob >> grammar
sentence.draw(figsize=(5, 5))
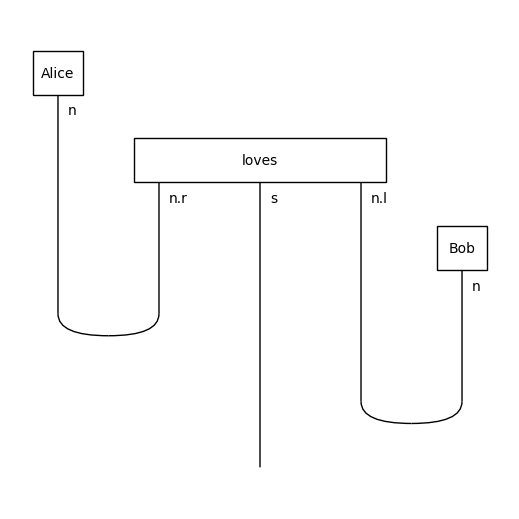
Note that although in this tutorial we draw all our diagram by hand, this parsing process can be automated. Indeed once you fix a dictionary, i.e. a set of words with their possible grammatical types, it is completely mechanical to decide whether a sequence of words is grammatical. More precisely, it takes \(O(n^3)\) time to decide whether a sequence of length \(n\) is a sentence, and to output the diagram for its grammatical structure.
Such a dictionary is called a pregroup grammar, introduced by Lambek in 1999 and has been used to study the syntax of English, French, Persian and a dozen of other natural languages. Note that pregroup grammars are as expressive as the better known context-free grammar, where the diagrams are called syntax trees.
Exercise: Draw the diagram of a sentence in a language with a different word order, e.g. Japanese.
Exercise: Draw the diagram of a sentence in a language written right to left, e.g. Arabic.
Reading: Check out Lambek’s From word to sentence, pick your favorite example and implement it in DisCoPy.
Now the main idea behind DisCoCat (categorical compositional distributional) models is to interpret each word as a vector and the grammatical structure as a linear map. Composing the tensor of word vectors with the linear map for grammar yields the meaning of the sentence. Another way to say this is in the language of tensor networks: computing the meaning of a sentence corresponds to tensor contraction along the grammatical structure.
Yet another way to say the same thing is in the language of category theory: computing the meaning of a sentence corresponds to the evaluation of a (strong monoidal) functor from a pregroup grammar to the category of linear maps. Maybe that last sentence puts you off, since category theory is also known as “generalised abstract nonsense”. Don’t worry, you don’t need to remember pages of axioms to use DisCoPy, it keeps track of them for you.
Let’s build a simple toy model where:
we map
nto2, i.e. we encode a noun as a 2d vector,we map
sto1, i.e. we encode a sentence as a scalar,we map
AliceandBobto[0, 1]and[1, 0], i.e. we encode them as the basis vectors,we map
lovesto the matrix[[0, 1], [1, 0]], i.e.Alice loves BobandBob loves Alice.
[43]:
F = tensor.Functor(
ob_map={n: 2, s: 1},
ar_map={Alice: [0, 1], loves: [0, 1, 1, 0], Bob: [1, 0]},
dom=Diagram)
print(F(Alice @ loves @ Bob))
print(F(grammar))
assert F(Alice @ loves @ Bob >> grammar).array == 1
Tensor[int]([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0], dom=Dim(1), cod=Dim(2, 2, 2, 2))
Tensor[int]([1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1], dom=Dim(2, 2, 2, 2), cod=Dim(1))
Since F(sentence).array == 1, we conclude that the sentence is true, i.e. Alice loves Bob!
If we evaluate the meaning of noun phrases rather than sentences, we get vectors that we can compare using inner products. This gives us a similarity measure between noun phrases. In our toy model, we can say that Alice and Bob are different: we defined their meaning to be orthogonal.
[44]:
assert not F(Alice) >> F(Bob).dagger()
Equation(Alice, Bob, symbol="$\\neq$").draw(figsize=(3, 1))
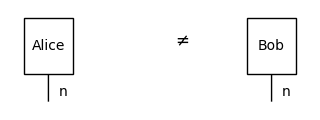
Let’s define some more words:
we map
manto[1, 0], i.e. Bob is the only man in our model,we map the adjective
richof typen @ n.lto the projector[[1, 0], [0, 0]], i.e. only Bob is rich.
[45]:
rich, man = Word("rich", n @ n.l), Word("man", n)
F.ar_map[rich], F.ar_map[man] = [1, 0, 0, 0], [1, 0]
rich_man = rich @ man >> Id(n) @ Cup(n.l, n)
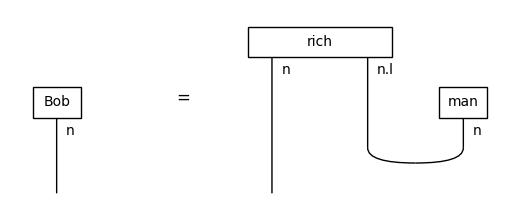
assert F(Bob) >> F(rich_man).dagger() # i.e. Bob is a rich man.
Equation(Bob, rich_man).draw(figsize=(5, 2))
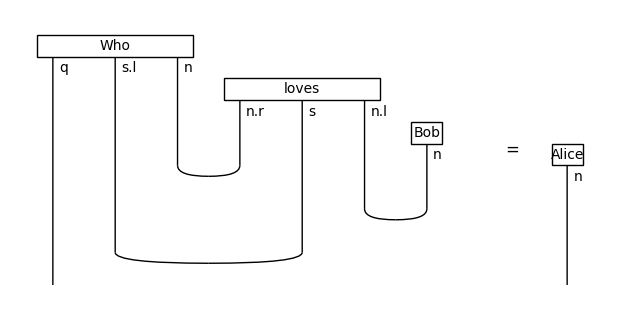
If we draw the diagram of a Who? question, the inner product with a noun phrase measures how well it answers the question.
[46]:
q = Ty('q')
Who = Word("Who", q @ s.l @ n)
F.ob_map[q], F.ar_map[Who] = 2, [1, 0, 0, 1]
question = Who @ loves @ Bob\
>> Id(q @ s.l) @ Cup(n, n.r) @ Id(s) @ Cup(n.l, n)\
>> Id(q) @ Cup(s.l, s)
answer = Alice
assert F(question) == F(answer)
Equation(question, answer).draw(figsize=(6, 3))
Exercise: Draw your favorite sentence, define the meaning of each word then evaluate it as a tensor.
Exercise: Build a toy model with a 4-dimensional noun space, add Charlie and Diane to the story.
Exercise: Define the meaning of the word Does and draw the diagram for the yes-no question Does Alice love Bob?. The meaning of the question should be the same as the sentence Alice loves Bob, i.e. the answer is “yes” if the sentence is true.
Putting it all together#
Let’s recap what we’ve seen so far:
Diagrams can represent any cooking recipe, functors translate recipes.
Diagrams can represent any tensor network, tensor functors contract the network.
Diagrams can represent any quantum circuit, tensor functors simulate the circuit.
Diagrams can represent any grammatical sentence, tensor functors compute the meaning.
Now we’ve got all the ingredients ready for some quantum natural language processing! Indeed, the key insight behind QNLP is that instead of computing a functor \(F : \mathbf{Grammar} \to \mathbf{Tensor}\) classically, we can split the computation into two steps \(F = \mathbf{Grammar} \xrightarrow{F'} \mathbf{Circuit} \xrightarrow{\mathrm{eval}} \mathbf{Tensor}\): first we translate our grammatical structure into a quantum circuit, then we evaluate that quantum circuit to compute the meaning of the sentence.
[47]:
from discopy.quantum import circuit, qubit, sqrt, X
F_ = circuit.Functor(
ob_map={s: qubit ** 0, n: qubit ** 1},
ar_map={Alice: Ket(0),
loves: sqrt(2) @ Ket(0, 0) >> H @ X >> CX,
Bob: Ket(1)})
F_.dom = Diagram
F_(sentence).draw(figsize=(6, 6))
assert F_(sentence).eval().is_close(F(sentence).cast(complex))
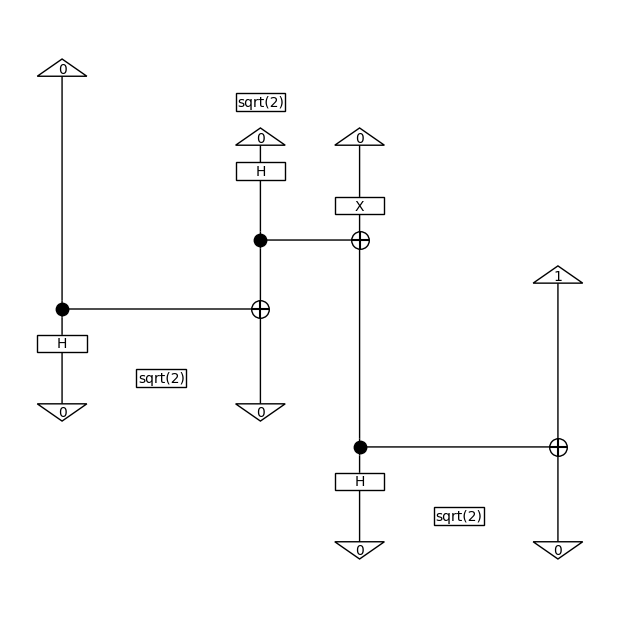
Of course this is a toy example: we’ve picked by hand what the circuits for Alice, loves and Bob should be so that they fit our interpretation. In order to apply our QNLP model to the real world, we need to learn from data what the circuits should be. In practice, we pick a parametrised circuit for each type of word, an ansatz, we then tune the parameters so that they reproduce our data.
Reading: Check out the alice-loves-bob notebook, where we use JAX to simulate a toy QNLP model that learns the meaning of the verb “loves”. In bob-is-rich, we show a slightly more complex example where the GHZ state is used to encode the meaning of relative pronouns.
Reading: Check out the qnlp-experiment where we run these toy models on quantum hardware.
Exercise: Run your own QNLP experiment on quantum hardware! There are multiple parameters that you can try to scale: the length of sentences, the size of the vocabulary, the number of qubits for the noun space.
Exercise: Implement a swap test to compute whether “Alice” is an answer to “Who loves Bob?”.
References#
Coecke, B., Sadrzadeh, M., & Clark, S. (2010) Mathematical foundations for a compositional distributional model of meaning. arXiv:1003.4394
Zeng, W., & Coecke, B. (2016) Quantum algorithms for compositional natural language processing. arXiv:1608.01406
de Felice, G., Toumi, A., & Coecke, B. (2020) DisCoPy: Monoidal Categories in Python. arXiv:2005.02975
Meichanetzidis, K., Toumi, A., de Felice, G., & Coecke, B. (2020) Grammar-Aware Question-Answering on Quantum Computers. arXiv:2012.03756
Meichanetzidis, K., Gogioso, S., De Felice, G., Chiappori, N., Toumi, A., & Coecke, B. (2020) Quantum natural language processing on near-term quantum computers. arXiv:2005.04147